How Language Models Actually Work · Chapter 2 · Lesson 4 · 7 min read
Inside the transformer block
Lesson 2 promised that each block in the stack “refines” the token vectors. This lesson opens the block and shows the machinery. There are two main components, and they divide the work cleanly: self-attention moves information between tokens, and the feed-forward network processes each token on its own. Everything else in the block exists to keep the stack trainable.
Attention lets every token gather information from the tokens before it; the feed-forward network then thinks about what was gathered.
The problem attention solves
Take the sentence “The animal didn’t cross the street because it was too tired.” What does “it” refer to? To represent “it” well, the model must pull information from “animal”, several positions away. Word meaning depends on context, and context lives in other tokens. The block needs a mechanism for tokens to exchange information, selectively: “it” should draw heavily from “animal”, barely from “street”.
Queries, keys, and values
Self-attention implements this exchange with a metaphor from retrieval. From its incoming vector, every token computes three new vectors using three learned weight matrices:
- a query : what this token is looking for (“I am a pronoun, seeking a recent noun”)
- a key : what this token offers, its advertisement (“I am an animal noun”)
- a value : the actual content this token will hand over if selected
Each token’s query is compared against every other token’s key. A strong query-key match means “this token is relevant to me”, and the matching token’s value is blended into the result, in proportion to the match strength.
The attention formula
The whole mechanism, computed for all tokens at once, is:
Piece by piece: , , and are matrices holding the query, key, and value vectors of every token, one row per token. The product computes the dot product of every query with every key, giving a table of raw relevance scores between every pair of tokens, exactly the similarity measurement of lesson 1.7 put to work. is the dimension of the key vectors, and dividing by keeps the scores in a moderate range so that softmax does not saturate. The softmax, applied to each token’s row of scores, turns relevance into attention weights: positive numbers summing to 1, a recipe for blending. Multiplying by executes the recipe: each token’s output is the weighted average of all the value vectors, dominated by the tokens it attends to most.
In a model that generates left to right, one restriction applies: a token may only attend to itself and earlier positions, never to the future. This causal mask simply sets all forbidden scores to negative infinity before the softmax, zeroing their weights, and it exists because the model must predict the next token without peeking at it.
Multi-head attention
A single attention pattern is one lens: perhaps it tracks pronoun references. But syntax, nearby words, and topic-level signals matter at the same time. So the block runs many attention operations in parallel, each with its own learned , , matrices and its own pattern. Each parallel instance is a head, the arrangement is multi-head attention, and typical models run dozens of heads per block. Their outputs are concatenated and mixed back to dimension .
The feed-forward network
After attention has gathered context into each token’s vector, the second component processes it. The feed-forward network (FFN) is a small two-layer neural network applied to each token’s vector independently, identically at every position. No information moves between tokens here; that was attention’s job. The FFN is where much of the model’s stored knowledge appears to live, and it holds roughly two thirds of the block’s parameters. A serviceable mental model: attention gathers, the FFN thinks.
The supporting cast
Two more pieces appear in every block diagram, each needing one paragraph:
- Residual connections: the block’s output is computed as input plus refinement, , rather than replacing outright. Each block contributes an adjustment to a running stream. This is what lets gradients flow through a hundred stacked blocks during training without dying out.
- Layer normalization: a rescaling step before each component that keeps the numbers in each vector in a healthy range, stabilizing training. Bookkeeping, not intelligence.
The block in one picture
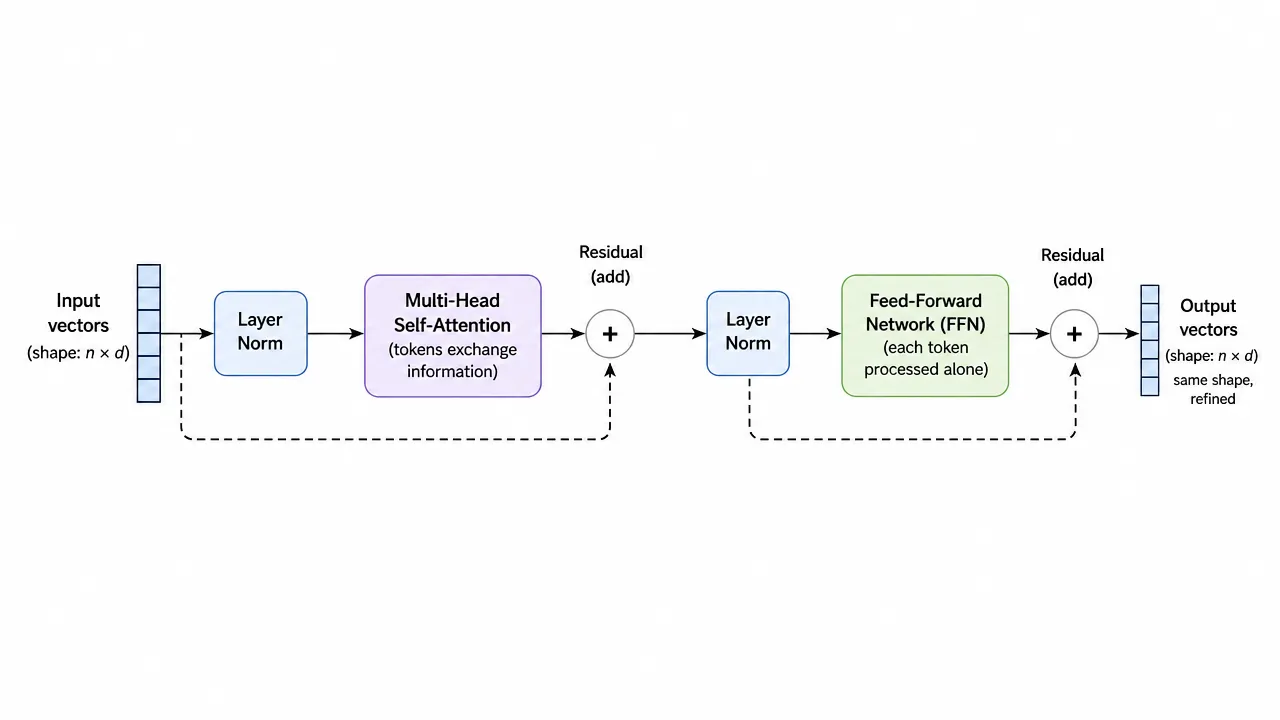
Stack this block N times and you have the body of every modern LLM.
Attention compares every token with every other token, and that phrase should sound expensive. In the next lesson we count the cost, and meet the limit it imposes: the context window.