How Language Models Actually Work · Chapter 2 · Lesson 1 · 4 min read
Inputs and outputs of a trained LLM
Chapter 1 ended with text converted into vectors and fed “into the model”. This chapter opens the model. Before looking at any internals, the most useful step is to treat the whole trained transformer as a black box and pin down exactly what goes in and what comes out. The answer is simpler than most people expect.
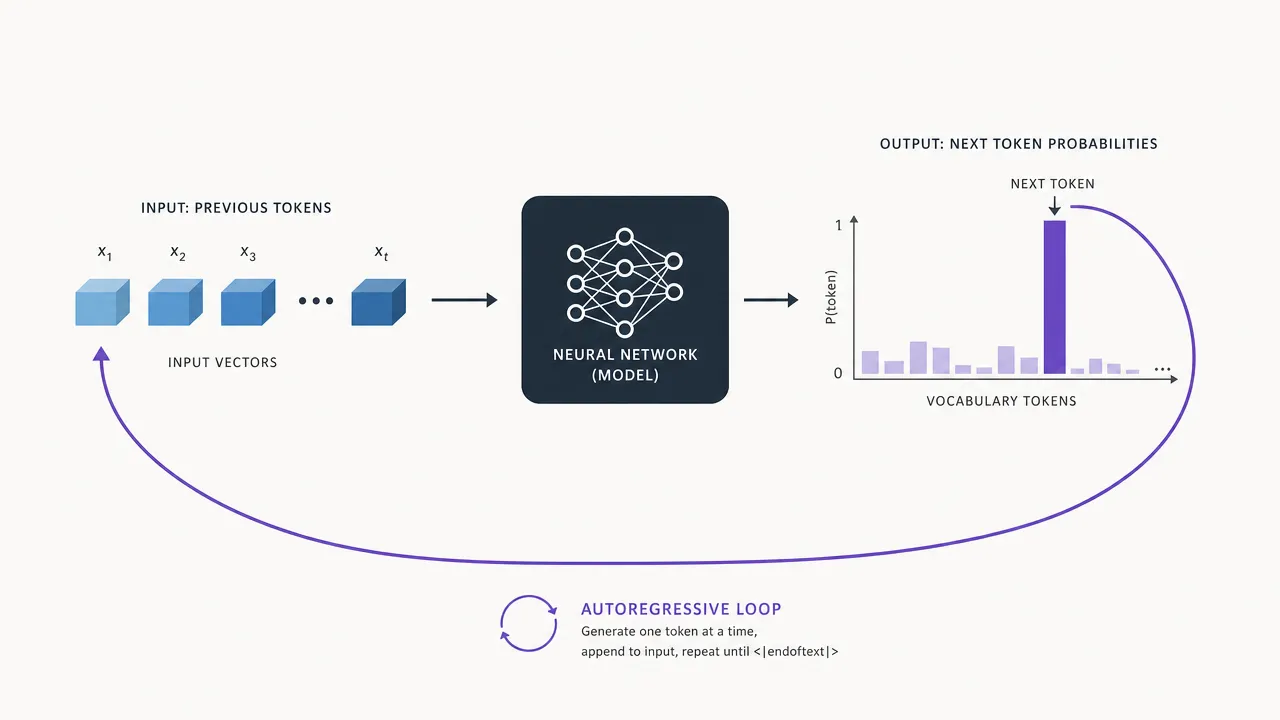
A language model has one job: given a sequence of tokens, output a probability for every token in its vocabulary being the next one.
The input
The input is what Chapter 1 built: a sequence of token IDs, turned into embedding vectors with position stamped in. Nothing else. The model has no memory of previous requests, no clock, no knowledge of who is asking. Everything it can use must be inside this one sequence, which is why the chat template of lesson 1.5 packs the entire conversation into it every single time.
The output
The output side is where the surprise lives. The model does not output a word, a sentence, or an answer. After the input flows through the network, the final layer, called the LM head, produces one raw score for every token in the vocabulary. These raw scores are called logits: one number per vocabulary entry, around 50,000 to 200,000 numbers, higher meaning “more likely to come next”. Logits can be any value, positive or negative, and do not sum to anything meaningful, so they are passed through the softmax function:
Piece by piece: is the logit for token , and exponentiates it, making every score positive and stretching gaps between high and low scores. The denominator sums the exponentiated scores of all vocabulary tokens. Dividing by it forces all the results to add up to exactly 1. The output is therefore a proper probability: the model’s confidence that token comes next.
So for the input “The cat sat on the”, the output is a 50,000-entry probability table where ” mat” might get 0.32, ” floor” 0.11, ” roof” 0.07, and ” carburetor” something near zero.
The loop that produces text
One probability table predicts one token. Whole paragraphs come from the autoregressive loop:
- Feed the sequence in, get the probability distribution out.
- Choose one token from the distribution (the subject of lesson 3).
- Append the chosen token to the sequence.
- Repeat from step 1 until a stop condition, such as the
<|endoftext|>token.
That is all generation is. When a chatbot “types” its answer word by word, you are watching this loop run, one full pass through the model per token. The loop also explains a fact worth internalizing early: the model never plans a full answer in advance. Each token is chosen with no commitment about the tokens after it.
We now know what enters and what exits. The next lesson opens the box one level and names the components the input flows through.