How Language Models Actually Work · Chapter 2 · Lesson 2 · 4 min read
Components of the forward pass
A forward pass is one complete trip of the input through the network, producing one output distribution. The name distinguishes it from the backward pass used during training, where errors flow back through the network to adjust the weights. A deployed model only ever runs forward: its weights are frozen, and nothing it processes changes it. This lesson names the stations the input passes through.
A transformer LLM is three stages: an embedding layer, then a tall stack of identical transformer blocks, then the LM head.
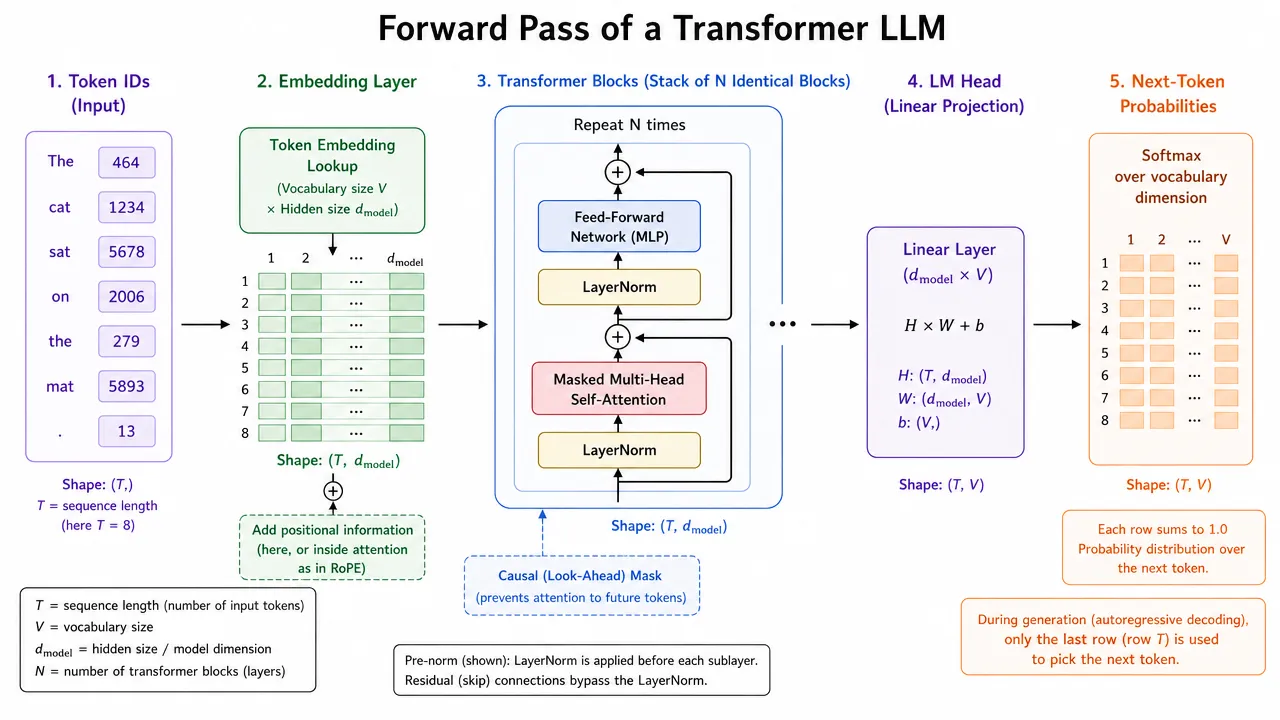
Stage 1: the embedding layer
Familiar territory. Token IDs select rows of the embedding matrix , position information is stamped in, and the sequence of tokens becomes a sequence of vectors. One vector per token, each with numbers, where is the model dimension from lesson 1.6.
Stage 2: the stack of transformer blocks
The body of the model is a stack of transformer blocks: anywhere from a dozen in small models to over a hundred in frontier ones. The blocks are architecturally identical, each with its own learned weights, and they run strictly in order. Each block takes in the sequence of vectors and outputs a refined sequence of the same shape: same number of tokens, same dimension , different values.
The shape never changing is the key design fact. Because every block’s output looks exactly like its input, blocks can be stacked like floors of a building, and making a model “deeper” is simply adding floors. What changes across the floors is the content of the vectors. A vector enters the stack representing roughly “this token at this position” and exits representing something far richer: that token in the light of everything relevant around it. By the top of the stack, the vector at the word “bank” in “river bank” and the one in “bank account” have moved far apart, even though both started from the same embedding row.
What happens inside one block, the actual refining machinery, is the deepest topic of this chapter and gets its own lesson (lesson 4).
Stage 3: the LM head
After the final block, the vector at the last position of the sequence is handed to the LM head: one final layer that maps a vector of numbers to numbers, one logit per vocabulary token. Softmax turns the logits into the probability distribution of lesson 1. Why the last position? Because in a model reading left to right, the last token’s vector is the one that has absorbed the entire sequence, making it the natural summary from which to predict what comes next.
The whole pass in one picture
token IDs
→ embedding layer vectors, one per token
→ block 1 → block 2 → ... → block N same shape, increasingly refined
→ LM head (at last position) → logits → softmax
→ probability distribution over the vocabularyThe model has now handed us a probability table with tens of thousands of entries. Somebody still has to pick exactly one token from it, and that choice is where a model’s “personality” settings like temperature live. That is the next lesson.